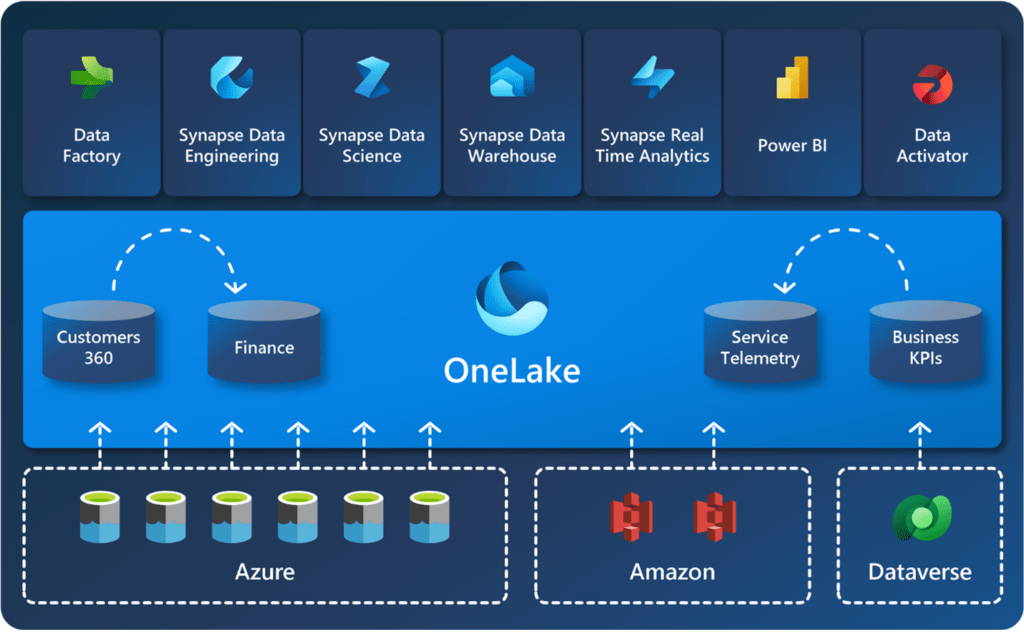
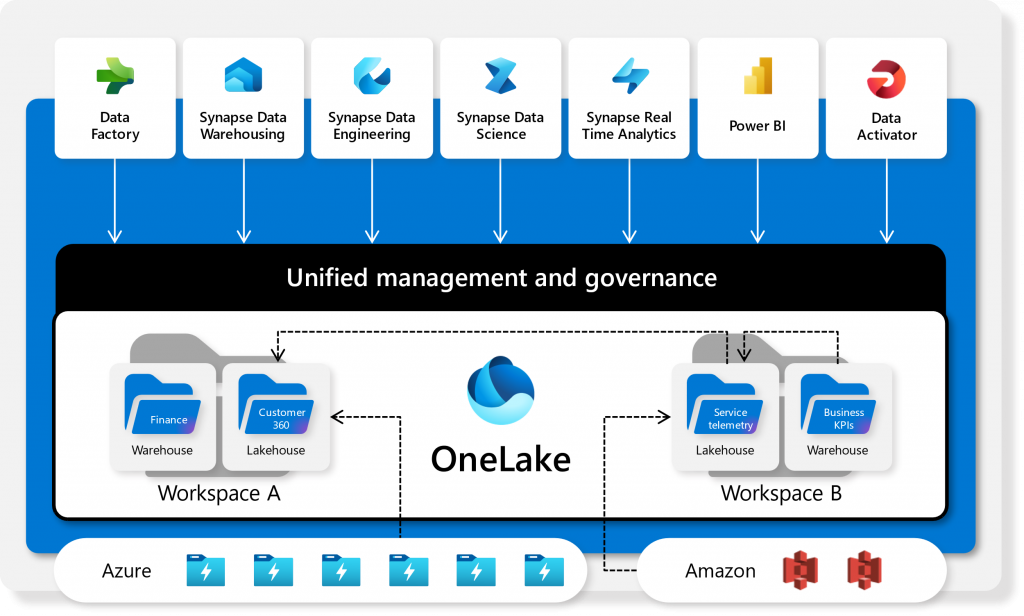
OneLake is a unified, scalable data lake solution within Microsoft Fabric that allows organizations to store, manage, and analyze large amounts of structured and unstructured data in a single, centralized repository. It streamlines data access and collaboration across various teams, enabling seamless integration with other Microsoft tools for faster insights and decision-making. OneLake simplifies data management, ensuring secure, real-time access to valuable information while optimizing costs and resources.
Cross-functional analysis
Unified data storage allows for comprehensive analyses across departments. For instance, marketing and sales teams can work together on the same customer data, performing joint analyses without needing separate storage systems.
Data-driven decision-making
With a single source of truth, decision-makers have timely, consistent data for more accurate reporting and forecasting.
Operational efficiency
The centralized model supports operational efficiency by reducing the time and resources spent on data consolidation and cleaning, as all data lives in a single, organized repository.
Unified data access across multiple sources
Shortcuts enable seamless integration of data from various sources—including Azure Data Lake Storage (ADLS) Gen2, Amazon S3, Google Cloud Storage, and on-premises systems—into a single virtual data lake. This unification allows users to access and analyze data across different platforms without the need for data movement or duplication
Elimination of data duplication & movement
By referencing data in its original location, shortcuts prevent unnecessary data duplication and movement. This approach reduces storage costs and minimizes the latency associated with data transfers, leading to more efficient data management.
Cross-domain & cross-cloud data integration
Shortcuts facilitate the integration of data across different domains and cloud platforms, creating a cohesive data environment. This capability supports complex data architectures, such as data mesh and medallion architectures, by allowing data to be reused across various domains and capacities without altering ownership or creating multiple copies.
Seamless data interoperability
By utilizing open data formats like Delta Parquet, OneLake ensures that data is accessible and usable across various analytical tools and platforms. This interoperability eliminates the need for data conversions or proprietary formats, facilitating smoother data integration and analysis.
Efficient data management
The combination of open formats and multi-engine support allows OneLake to store a single copy of data that can be processed by different analytical engines, such as T-SQL, Apache Spark, and Analysis Services. This approach reduces data duplication, minimizes storage requirements, and streamlines data governance processes.
Enhanced flexibility & performance
With multi-engine support, users can select the most appropriate analytical engine for their specific tasks, optimizing performance and resource utilization. For instance, data engineers can use Apache Spark for large-scale data processing, while business analysts might prefer T-SQL for structured queries, all operating on the same dataset without additional data movement.